|
LEVEL 8
- 积分
- 404
- 金币
- 20338 枚
- 威望
- -1 点
- 金镑
- 0 个
- 银币
- 133 枚
- 舍利
- 0 枚
- 注册时间
- 2009-1-26
- 最后登录
- 2025-3-22
|
1楼
大 中
小 发表于 2017-9-25 12:16 只看该作者

!!!全体会员请注意!!!
任何VIP优惠活动,都是骗人的!
切勿上当受骗!

请大家记住并收藏备用访问地址:
地址一
地址二
地址三
地址四
地址五
忘记地址,请发email索取:
getsisurl#gmail.com(#换成@)
【科技】资源 | 从最小二乘到DNN:六段代码了解深度学习简史[9p]
机器之心
2017-09-24 12:57
选自floydhub
参与:路雪、刘晓坤、黄小天
六段代码使深度学习发展成为今天的模样。本文介绍它们的发明者和背景。每个故事包括简单的代码示例,均已发布到 FloydHub 和 GitHub 上,欢迎一起探讨。
FloydHub 地址: https://www.floydhub.com/emilwal ... rning-from-scratch/
GitHub 地址: https://github.com/emilwallner/Deep-Learning-From-Scratch

要想在 FloydHub 上运行代码示例,请确保已经安装 floyd 命令行工具,并将我提供的代码示例复制到你的本地电脑上。如果你是新手,可以先阅读我之前的博客《My First Weekend of Deep Learning》(地址: http://blog.floydhub.com/my-first-weekend-of-deep-learning/)。在本地电脑的示例项目文件夹中创建 CLI 之后,即可使用下列命令在 FloydHub 上运行该项目:
floyd run --data emilwallner/datasets/mnist/1:mnist --tensorboard --mode jupyter
最小二乘法
深度学习都从这个数学片段开始的(我已经把它翻译成 Python):
# y = mx b
# m is slope, b is y-intercept
defcompute_error_for_line_given_points(b,m,coordinates):totalError =0fori inrange(0,len(coordinates)):x =coordinates [0]y =coordinates[1]totalError =(y -(m *x b))**2returntotalError /float(len(coordinates))
# example
compute_error_for_line_given_points(1,2,[[3,6],[6,9],[12,18]])
这个算法由法国数学家 Adrien-Marie Legendre 首次发表(1805, Legendre),他的另一大成就是确立标准米。他沉迷于预测彗星的位置。他根据彗星之前的几个位置进行不懈搜索,寻找计算彗星轨迹的方法。
这真的是愚公移山一样的工作。他尝试了多种方法,终于找到了一个方法:首先猜测彗星未来的位置,然后平方误差,最后重新猜测以减少平方误差的总和。这就是线性回归损失函数的基础。
在 Jupyter notebook 上运行上述代码,并逐渐熟悉它。m 代表系数(coefficient),b 代表预测中的常量,coordinates 代表彗星的位置。目的就是找到 m 和 b 的一种组合,使误差最小化。

这就是深度学习的核心:给出输入和期望的输出,搜索二者之间的相关性。
梯度下降
Legendre 的手动尝试减少误差率的方法比较费时。一个世纪后,来自荷兰的诺贝尔奖获得者 Peter Debye 创造了一种解决方案(1909, Debye)。
我们想象 Legendre 关心的参数为X,Y 轴代表每个X值的误差值,Legendre 搜索产生最小误差的X。在下图中,我们可以看到当X = 1.1 时,误差 Y 的值最小。
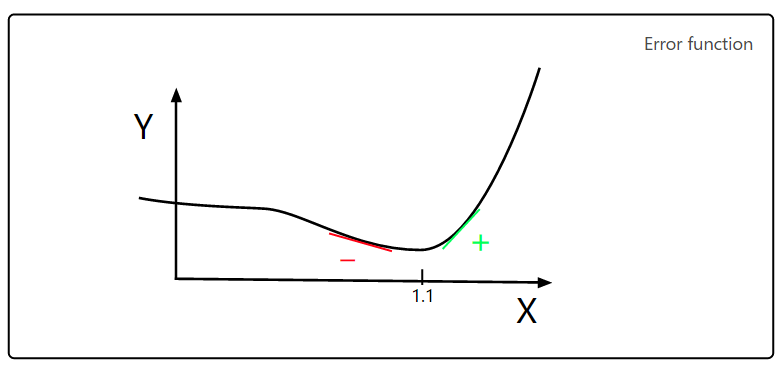
Peter Debye 注意到最小值左侧的偏斜度是负值,右侧是正值。因此,如果你知道任意 X 的斜率,就可以找到 Y 的最小值。
这就引出了梯度下降方法,几乎每个深度学习模型都使用了梯度下降。
我们假设误差函数是
为了了解任意 X 值的斜率,我们使用它的导数
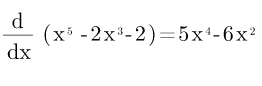
如果你需要了解更多关于梯度下降的相关知识,可以查阅:
Debye 的数学片段也已经翻译成了 Python:
current_x =0.5# the algorithm starts at x=0.5
learning_rate =0.01# step size multiplier
num_iterations =60# the number of times to train the function
#the derivative of the error function (x**4 = the power of 4 or x^4)
defslope_at_given_x_value(x):return5*x**4-6*x**2
# Move X to the right or left depending on the slope of the error function
fori inrange(num_iterations):previous_x =current_x current_x =-learning_rate *slope_at_given_x_value(previous_x)print(previous_x)print("The local minimum occurs at %f"%current_x)
这里使用的技巧是 learning_rate。通过向坡度的相反方向前进,接近最小值。此外,越接近最小值,坡度越小。随着坡度趋近于零,每前进一步,误差都将减小。
线性回归
将最小二乘法和梯度下降结合起来就得到线性回归。在二十世纪五六十年代,一组实验经济学家在早期计算机上实现了这些想法。该逻辑在穿孔卡片(真正手工制造的软件程序)上得到实现。他们花费数天准备这些卡片,用了多达 24 个小时的时间在计算机上运行一次回归分析。
这里是翻译成 Python 的线性回归示例(这样你就不用在穿孔卡片上实验了):
#Price of wheat/kg and the average price of bread
wheat_and_bread =[[0.5,5],[0.6,5.5],[0.8,6],[1.1,6.8],[1.4,7]]
defstep_gradient(b_current,m_current,points,learningRate):b_gradient =0m_gradient =0N =float(len(points))fori inrange(0,len(points)):x =points[0]y =points[1]b_gradient =-(2/N)*(y -((m_current *x) b_current))m_gradient =-(2/N)*x *(y -((m_current *x) b_current))new_b =b_current -(learningRate *b_gradient)new_m =m_current -(learningRate *m_gradient)return[new_b,new_m]
defgradient_descent_runner(points,starting_b,starting_m,learning_rate,num_iterations):b =starting_b m =starting_m
fori inrange(num_iterations):b,m =step_gradient(b,m,points,learning_rate)return[b,m]gradient_descent_runner(wheat_and_bread,1,1,0.01,100)
本质上,这种方法不会引入任何新东西,但是把误差函数和梯度下降结合起来的过程总是有一点纠结。运行以上代码,试着运行该线性回归模拟器(https://www.mladdict.com/linear-regression-simulator)。
感知机
在白天解剖白鼠大脑,在夜里寻找外星生物的 Frank Rosenblatt 登场。在 1958 年,他登上了纽约时报的头条:「New Navy Device Learns By Doing」with a machine that mimics a neuron (1958, Rosenblatt)。
给 Rosenblatt 的机器展示 50 对照片,每对照片中的两张各有一个不同的标记,机器可以在没有经过预编程的前提下将一对图片区分开来。这个结果使当时的公众对能真正学习的机器的可能性感到着迷。
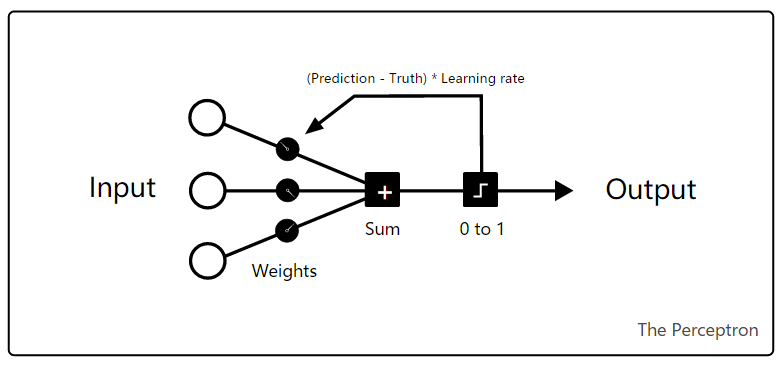
在每一个训练周期,将数据从左边输入,并随机初始化所有的权重,然后将输入加和。如果和是负值,输出为 0,否则为 1。
当预测是正确的时候,该周期中的权重不会发生变化。如果预测结果是错的,通过将误差乘以学习率(learning rate)调整权重的值。
试着用 OR(或)逻辑运行感知机:
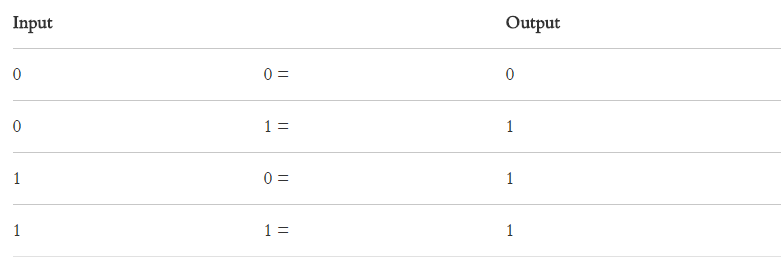
感知机翻译成 Python:
fromrandom importchoice fromnumpy importarray,dot,random 1_or_0 =lambdax:0ifx <0else1
training_data =[(array([0,0,1]),0),(array([0,1,1]),1),(array([1,0,1]),1),(array([1,1,1]),1),]
weights =random.rand(3)
errors =[]
learning_rate =0.2
num_iterations =100
fori inrange(num_iterations):input,truth =choice(training_data)result =dot(weights,input)error =truth -1_or_0(result)errors.append(error)weights =learning_rate *error *input
forx,_ intraining_data:result =dot(x,w)print("{}: {} -> {}".format(input[:2],result,1_or_0(result)))
在感知机被大肆宣传的一年后,Marvin Minsky 和 Seymour Papert 彻底否定了这个想法 (1969, Minsky & Papert)。当时,Minsky 和 Papert 在 MIT 运行着一个 AI 实验室。他们写了一本书,证明感知机只能解线性问题,并且批评了多层感知机的想法。遗憾的是,两年后,Frank Rosenblatt 遭遇船难离世了。
Minsky 和 Papert 的书发表仅一年后,一个芬兰硕士生发现了利用多层感知机解非线性问题的理论 (Linnainmaa, 1970)。由于当时主流对感知机持批评态度,对 AI 的投资枯竭了十多年。这就是众所周知的 AI 的第一个冬天。
Minsky 和 Papert 对感知机的有力批评在于 XOR(与或)问题的讨论上。其中的逻辑和 OR 逻辑一样,只有一个期望值,当有两个为真的声明时(1 & 1),返回值为假(0)。
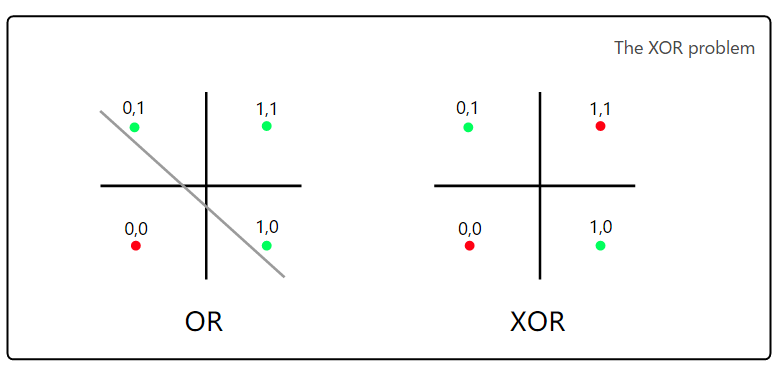
在 OR 逻辑中,分离真组合和假组合是可能的。但很明显的是,用线性函数分离 XOR 逻辑是不可能的。
人工神经网络
到了 1986 年,几个实验证明了神经网络可以用来解决复杂的非线性问题 (Rumelhart et al., 1986)。当时,计算机的速度比起理论提出的时候已经快了 10,000 倍。Rumelhart 等人介绍他们的传奇论文如下:
「我们为类神经元单元组成的网络加入了新的学习过程,反向传播。反向传播不断重复调整网络连接的权重,以最小化网络的实际输出向量和期望输出向量之间的差异。经过权重调整之后,网络内部的隐藏单元(不包括输入层和输出层)可以表示任务范围的重要特征,并通过单元间的相互作用捕捉任务中的规律。神经网络创建有用的新特征的能力使其区别于早先提出的更简单的反向传播方法,比如感知机收敛过程(perceptron-convergence procedure)。」Nature 323, 533 - 536 (09 October 1986)
为了理解论文的核心内容,我们将使用 DeepMind 的 Andrew Trask 实现代码。这可不是一段随意写出来的代码,它在 Andrew Karpathy 的 Stanford 深度学习课程和 Siraj Raval 的 Udacity 课程中被使用过。除此之外,它还解决了 XOR 问题,使 AI 研究度过了第一个冬天。
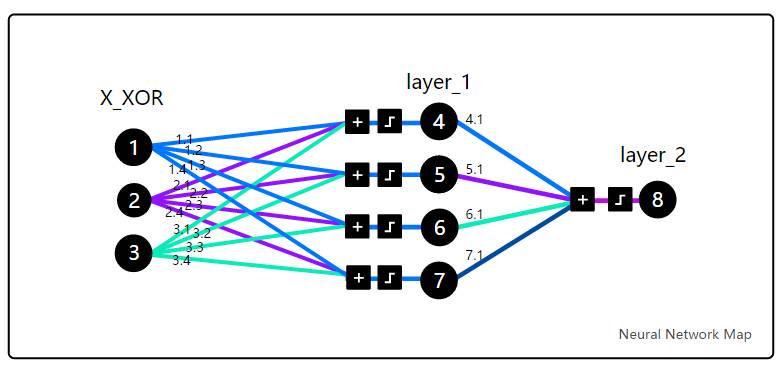
在深入讨论代码的细节之前,试着用一到两个小时运行这个模拟器(https://www.mladdict.com/neural-network-simulator)领会其中的核心逻辑。然后阅读 Trask 的博客(http://iamtrask.github.io/2015/07/12/basic-python-network/),然后再重看四遍。注意 X_XOR 数据中添加的参量 [1] 是偏置神经元(bias neurons,https://stackoverflow.com/questi ... -in-neural-networks),它们的作用和线性函数的常量是一样的。
importnumpy asnpX_XOR =np.array([[0,0,1],[0,1,1],[1,0,1],[1,1,1]])
y_truth =np.array([[0],[1],[1],[0]])
np.random.seed(1)
syn_0 =2*np.random.random((3,4))-1
syn_1 =2*np.random.random((4,1))-1
defsigmoid(x):output =1/(1 np.exp(-x))returnoutput
defsigmoid_output_to_derivative(output):returnoutput*(1-output)
forj inrange(60000):layer_1 =sigmoid(np.dot(X_XOR,syn_0))layer_2 =sigmoid(np.dot(layer_1,syn_1))error =layer_2 -y_truth layer_2_delta =error *sigmoid_output_to_derivative(layer_2)layer_1_error =layer_2_delta.dot(syn_1.T)layer_1_delta =layer_1_error *sigmoid_output_to_derivative(layer_1)syn_1 -=layer_1.T.dot(layer_2_delta)syn_0 -=X_XOR.T.dot(layer_1_delta)
print("Output After Training: n",layer_2)
反向传播、矩阵乘法以及随机梯度下降的组合令人难以理解。为了简要理解其背后发生了什么,通常会将过程可视化,只需要理解其中的逻辑,而不需要对其建立完整的心理图像。
此外,还可以观看 Andrew Karpathy 的反向传播的讲座(https://www.youtube.com/watch?v=i94OvYb6noo),概念的可视化(http://www.benfrederickson.com/numerical-optimization/),以及阅读 Michael Nielsen 的书中关于反向传播的章节(http://neuralnetworksanddeeplearning.com/chap2.html)。
还可以查阅详细的反向传播推导过程:
被 Geoffrey Hinton 抛弃,反向传播为何饱受质疑?(附 BP 推导)
深度神经网络
深度神经网络是指在输入层与输出层之间含有超过一个隐藏层的网络。它最早由 Rina Dechter 于 1986 年提出 (Dechter, 1986),并在 2012 年成为业界主流,伴随着 IBM Watson 在 Jeopardy 中大获全胜,以及谷歌大脑项目猫识别器的成功。
深度神经网络的核心结构一如既往,但现在被应用到了若干个不同问题上。正则化上也有很多提升,起初是一组简化噪音数据的数学函数(Tikhonov, A. N., 1963),现在被用于神经网络以提升泛化能力。
深度神经网络的很大一部分创新得益于算力的发展,加快了研究者的创新周期:八十年代中期一台计算机需要一年时间解决的问题,利用今天的 GPU 技术只需要半秒钟。
现在,计算成本的降低和深度学习库的发展使深度神经网络被大大普及。这里有一个常见的深度学习堆栈的例子,从最底层开始:
GPU>Nvidia Tesla K80。该硬件通常用作图形处理,比起 CPUs,在深度学习中通常 GPU 要快 50-200 倍。
CUDA>GPUs 的低级编程语言。
CuDNN>Nvdia 优化 CUDA 的库。
TensorFlow>Google 的深度学习框架,在 CuDNN 之上。
TFlearn>TensorFlow 的一个前端框架。
我们来看看 MNIST 的数字图像分类,它被称为深度学习中的「Hello World」。
TFlearn 的实现:
from__future__ importdivision,print_function,absolute_import
importtflearn
fromtflearn.layers.core importdropout,fully_connected
fromtensorflow.examples.tutorials.mnist importinput_data
fromtflearn.layers.conv importconv_2d,max_pool_2d
fromtflearn.layers.normalization importlocal_response_normalization
fromtflearn.layers.estimator importregression
# Data loading and preprocessing
mnist =input_data.read_data_sets("/data/",one_hot=True)
X,Y,testX,testY =mnist.train.images,mnist.train.labels,mnist.test.images,mnist.test.labelsX =X.reshape([-1,28,28,1])
testX =testX.reshape([-1,28,28,1])
# Building convolutional network
network =tflearn.input_data(shape=[None,28,28,1],name='input')
network =conv_2d(network,32,3,activation='relu',regularizer="L2")
network =max_pool_2d(network,2)
network =local_response_normalization(network)
network =conv_2d(network,64,3,activation='relu',regularizer="L2")
network =max_pool_2d(network,2)
network =local_response_normalization(network)
network =fully_connected(network,128,activation='tanh')
network =dropout(network,0.8)
network =fully_connected(network,256,activation='tanh')
network =dropout(network,0.8)
network =fully_connected(network,10,activation='softmax')
network =regression(network,optimizer='adam',learning_rate=0.01,loss='categorical_crossentropy',name='target')
# Training
model =tflearn.DNN(network,tensorboard_verbose=0)
model.fit({'input':X},{'target':Y},n_epoch=20,validation_set=({'input':testX},{'target':testY}),snapshot_step=100,show_metric=True,run_id='convnet_mnist')
还有很多很棒的文章能解释这个 MNIST 问题:
https://www.tensorflow.org/get_started/mnist/beginners
https://www.youtube.com/watch?v=NMd7WjZiCzc
https://www.oreilly.com/learning ... ial-with-tensorflow
如果想对 TFlearn 有一个更高层次的理解,可以看看我之前的文章。
结语
正如你在 TFlearn 实例中所见,深度学习的核心逻辑依然相似于 Rosenblatt 的感知器。当下的神经网络大多使用 Relu 激活函数而不是二分阶跃函数(binary Heaviside step function)。在卷积神经网络的最后一层中,损失等于 categorical_crossentropy。这是 Legendre 最小二乘法(Legendre‘s least square,)的演变,多重分类的逻辑回归。优化器 adam 源自 Debye 的梯度下降,Tikhonov 的正则化理念则在 dropout 层和正则化函数 L1/L2 的形式中广泛实现。
如果你想要更好地了解神经网络及其实现,请阅读我之前在 FloydHub 博客上写的文章:我学习深度学习的第一周(http://blog.floydhub.com/my-first-weekend-of-deep-learning/)。
原文地址:http://blog.floydhub.com/coding-the-history-of-deep-learning/
本文为机器之心编译,转载请联系本公众号获得授权。
声明:本文由入驻搜狐号的作者撰写,除搜狐官方账号外,观点仅代表作者本人,不代表搜狐立场。
[ 本帖最后由 druid169 于 2017-9-25 12:39 编辑 ]
|


